
dib - architecture::09.29.2016+14:47
Last time, I talked about my motivations for writing dib, my personal build system. This time we’re going to examine in depth the underlying architecture, with a focus on the types and execution.
Types
There are four fundamental types that form the structure of a build in dib (in order of increasing abstractness): SrcTransform, Gatherer, Stage, and Target. The first of these, SrcTransform represents the input and output of a command. There are four type constructors which represent the possible relationships of input to output:
- OneToOne - e.g. copying a file from one place to another, or building a .cpp into a .o file.
- OneToMany - e.g. extracting an archive, or writing out a converted file and some metadata
- ManyToOne - e.g. linking .o files into an executable, or archiving a bunch of files.
- ManyToMany - I don’t have any accessible examples for this, but I’ve seen use cases in my professional work.
Pipeline Overview
SrcTransforms are the actual data that the build is processing. They are the input to the entire process and are transformed as they move through each segment of the pipeline. They are initially generated by Gatherers. The Gatherers provided with dib only produce OneToOne transforms, the input being the files they gathered, with an empty string as the output. A Target can have more than one Gatherer; the output of each will be combined into a single list that is passed into the first Stage. Each of these Stages then does processing on the transforms that are passed in and passes them to the next Stage.
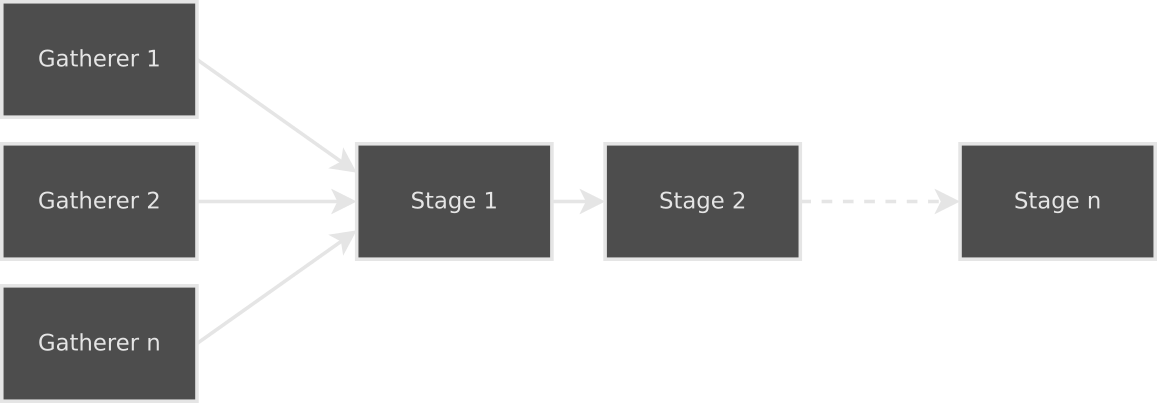
Stages
Each Stage takes as input a list of SrcTransforms and outputs either a list of SrcTransforms or an error string. At the beginning of every Stage sits an InputTransformer: a function that transforms the list of SrcTransforms into another list suitable for that Stage to process. In contrast to the other parts of a Stage (as we’ll soon see), this operates on the entire list to easily enable collation. The built-in C/C++ builder, for example, collates the list of OneToOne transforms of object files into a ManyToOne of object files to executable/library.
After passing through the InputTransformer, each SrcTransform is individually passsed into a DepScanner, an IO action that takes a SrcTransform and produces a SrcTransform. In the case of the C/C++ builder this is the CDepScanner, which recursively scrapes the includes for further, unique includes. It changes the input OneToOne transforms into ManyToOne and adds the dependencies after the actual source file to be built. When processing a Stage, the timestamps of the input files of each transform are checked to determine if the transform should be built. By adding the dependencies to the transform, the system takes care of rebuilding that transform when they change, for free.
The final piece of the Stage is the StageFunc, which is the actual business logic that executes the transform. This is a function that takes in a SrcTransform and returns either a SrcTransform or an error message. The returned SrcTransform should be one that is suitable to pass into the next stage. For the compilation stage of the C/C++ builder, this will be a OneToOne containing the object file. This whole process continues for each successive Stage.

Targets
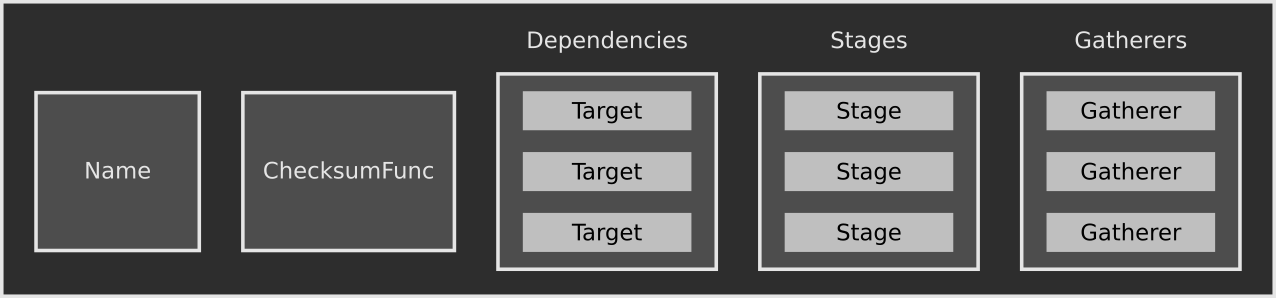
All of the previous pieces are encapsulated in the Target data type. A Target represents the input and final output product as a single unit. For example, a library or executable would each be a single Target; so too would the operation of copying a directory to a different location. A Target consists of a name string, a ChecksumFunc, a list of dependencies, a list of Stages in the order they are to be executed, and a list of Gatherers.
The name of a Target must be unique — not having unique names for all Targets, even if the difference is a debug build versus a release build, will cause unnecessary rebuilds. Therefore, if there are parameters that users can provide to change aspects of the build, those should be encoded into the Target name. The ChecksumFunc calculates a hash of parameters to determine if the Target should be force-rebuilt. As an example, changing the compile or link flags in the C/C++ builder will cause the checksum to change and rebuild the whole Target.
Execution Strategy
The original execution strategy for building transforms was relatively simple: spawn n futures (where n = number of cores), store those in a list, and have a list of the remaining transforms. Wait on the first item in the futures list and when it finishes, gather up all of the finished futures, check for errors, and spawn up to n again. Repeat until done. This strategy has two major problems. The first, more obvious one is that if the future being waited on takes longer than the rest in the list, there will be a lot of time during which cores are idle. The second issue only rears its head due to the garbage-collected nature of GHC Haskell. Making and updating these lists so often causes a massive amount of garbage to be created, so much so that for a build of a C++ codebase with 100 or so translation units, over a gigabyte of garbage was being generated.
This led me to write the current execution strategy, the code for which is more nuanced, but has better occupancy and generates significantly less garbage. I’m going to avoid getting into too much detail here — refer to the code for the exact implementation. The general idea is that there is a queue inside of an MVar, and instead of having implicit threads (previously represented with futures) to do work, there are explicit worker threads. Each of these workers grabs the queue from the MVar, peels off an item, and then puts the rest back. When there’s nothing left, the worker is done and signals this to the main thread. When all threads are done, execution stops and the final result is returned.
Next Time
Hopefully this has been an enlighting look at how dib works internally. The ideas behind it are fairly simple and straight-forward, even if the implementation is a bit tricky. I opted to leave out one topic, and that’s how the database (which tracks timestamps and hashes) works. In the next and final post, we’ll be looking at various areas that could stand to be improved and some thoughts on how to improve them.